
[OS]스케줄링 알고리즘
📚스케줄링 알고리즘
스케줄링 알고리즘에서 프로세스별 도착시간과 실행시간을 간단하게 예를 들어 평균대기시간과 평균반환시간을 구해보자.
평균대기시간과 평균반환시간을 구할 때 프로세스가 종료되는 시각과 새로운 프로세스의 도착 시각이 같은 경우가 있는데, 이 경우 새로 도착한 프로세스가 준비 큐에 먼저 들어가는 것을 임의로 가정했다.
| 프로세스 | A | B | C | D |
|---|---|---|---|---|
| 도착시간 | 0 | 2 | 4 | 5 |
| CPU사이클 | 6 | 4 | 1 | 3 |
📄FCFS 스케줄링
FCFS(First Come First Served) 스케줄링은 비선점 방식으로 스케줄링 알고리즘 중 가장 간단한 알고리즘이다. 프로세스는 준비 큐에 도착한 순서대로 디스패치되어 실행된다.
FCFS 스케줄링 알고리즘은 실행시간이 짧은 프로세스가 오래 기다릴 수도 있고 중요한 프로세스가 나중에 수행될 수도 있어 시분할 운영체제나 실시간 운영체제에 적합하지 않다.
위에서 예로든 프로세스 도착시간과 CPU사이클에 의한 FCFS 스케줄링 알고리즘의 결과는 아래와 같다.
0 6 10 11 14
| A | B | C | D |
프로세스 A는 시각 0에 도착하여 시각 6에 종료했으므로 반환시간은 6이다.
또한 준비 큐에 도착하고 바로 디스패치되었으므로 대기시간은 0이다.
프로세스 B는 시각 2에 도착하여 시각 10에 종료했으므로 반환시간은 8이다.
또한 시각 6에 디스패치되었으므로 대기시간은 4이다.
프로세스 C는 시각 4에 도착하여 시각 11에 종료했으므로 반환시간은 7이다.
또한 시각 10에 디스패치되었으므로 대기시간은 6이다.
프로세스 D는 시각 5에 도착하여 시각 14에 종료했으므로 반환시간은 9이다.
또한 시각 11에 디스패치되었으므로 대기시간은 6이다.
| 프로세스 | A | B | C | D |
|---|---|---|---|---|
| 대기시간 | 0 | 4 | 6 | 6 |
| 반환시간 | 6 | 4 | 7 | 9 |
평균대기시간: 4
평균반환시간: 5
📄SJF 스케줄링
SJF(Shortest Job First) 스케줄링은 준비 큐에서 기다리는 프로세스 중 실행시간이 가장 짧다고 예상되는 프로세스를 먼저 디스패치하여 실행하는 비선점 방식의 스케줄링 알고리즘이다. SJF 스케줄링은 CPU 사이클이 미리 주어져야만 적용 가능하다.
위에서 예로든 프로세스 도착시간과 CPU사이클에 의한 SJF 스케줄링 알고리즘의 결과는 아래와 같다.
0 6 7 10 14
| A | C | D | B |
프로세스 A는 시각 0에 도착하여 시각 6에 종료했으므로 반환시간은 6이다.
또한 준비 큐에 도착하고 바로 디스패치되었으므로 대기시간은 0이다.
프로세스 B는 시각 2에 도착하여 시각 14에 종료했으므로 반환시간은 12이다.
또한 시각 10에 디스패치되었으므로 대기시간은 8이다.
프로세스 C는 시각 4에 도착하여 시각 7에 종료했으므로 반환시간은 3이다.
또한 시각 6에 디스패치되었으므로 대기시간은 2이다.
프로세스 D는 시각 5에 도착하여 시각 10에 종료했으므로 반환시간은 5이다.
또한 시각 7에 디스패치되었으므로 대기시간은 2이다.
| 프로세스 | A | B | C | D |
|---|---|---|---|---|
| 대기시간 | 0 | 8 | 2 | 2 |
| 반환시간 | 6 | 12 | 3 | 5 |
평균대기시간: 3
평균반환시간: 6
📄SRT 스케줄링
SRT(Shortest Remaining Time) 스케줄링은 SJF 알고리즘의 선점 방식 버전이다. 준비 큐에서 기다리는 프로세스 중 남은 실행시간이 가장 짧다고 예상되는 것을 먼저 디스패치하여 실행시킨다.
준비 큐에 새로 들어온 프로세스의 예상 실행시간이 실행 중인 프로세스의 남은 실행시간 보다 짧을 경우 새로 들어온 프로세스가 즉시 디스패치된다. SRT 스케줄링도 프로세스의 CPU 사이클이 미리 주어져야만 적용 가능하다.
SRT 스케줄링은 선점을 위한 문맥 교환이 필요해 SJF보다 오버헤드가 크다. 실행 중인 프로세스가 거의 끝날 때 실행 예상시간이 매우 짧은 프로세스가 새로 입력되는 경우 선점에 따른 이득보다 문맥 교환의 오버헤드가 더 클 수 있다는 단점이 있다.
위에서 예로든 프로세스 도착시간과 CPU사이클에 의한 SRT 스케줄링 알고리즘의 결과는 아래와 같다.
0 2 4 5 7 10 14
| A | B | C | B | D | A |
프로세스 A는 시각 0에 도착하여 시각 14에 종료했으므로 반환시간은 14이다.
또한 시각 2부터 시각 10까지 준비 큐에서 대기했으므로 대기 시간은 8이다.
프로세스 B는 시각 2에 도착하여 시각 7에 종료했으므로 반환시간은 5이다.
또한 시각 4부터 시각 5까지 준비 큐에서 대기했으므로 대기 시간은 1이다.
프로세스 C는 시각 4에 도착하여 시각 5에 종료했으므로 반환시간은 1이다.
또한 준비 큐에서 도착 후 바로 디스패치되었으므로 대기 시간은 0이다.
프로세스 D는 시각 5에 도착하여 시각 10에 종료했으므로 반환시간은 5이다.
또한 시각 5부터 시각 7까지 준비 큐에서 대기했으므로 대기 시간은 2이다.
| 프로세스 | A | B | C | D |
|---|---|---|---|---|
| 대기시간 | 8 | 1 | 0 | 2 |
| 반환시간 | 14 | 5 | 1 | 5 |
평균대기시간: 2.75
평균반환시간: 6.25
📄RR 스케줄링
RR(Round Robin) 스케줄링은 디스패치된 프로세스가 할당 받은 시간 동안 작업을 하다가 작업을 완료하지 못하면 준비 큐의 마지막으로 가서 자기 차례를 기다리는 방식의 스케줄링 알고리즘이다.
RR 스케줄링은 프로세스가 도착한 순서대로 프로세스를 디스패치하지만 정해진 시간 할당량에 의해 실행을 제한한다. 따라서 시간 할당량에 따라 알고리즘의 성능이 좌우된다.
또한 RR 스케줄링은 선점형 스케줄링 알고리즘 중 가장 대표적인 방식이며 모든 작업이 완료될 때까지 계속 순환하면서 실행된다.
위에서 예로든 프로세스 도착시간과 CPU사이클에 의한 RR 스케줄링 알고리즘의 결과는 아래와 같다.(시간 할당량은 3으로 가정했다.)
0 3 6 9 10 13 14
| A | B | A | C | D | B |
프로세스 A는 시각 0에 도착하여 시각 9에 종료했으므로 반환시간은 9이다.
또한 시각 3부터 시각 6까지 준비 큐에서 대기했으므로 대기 시간은 3이다.
프로세스 B는 시각 2에 도착하여 시각 14에 종료했으므로 반환시간은 12이다.
또한 시각 3에 디스패치 되었고 시각 6부터 시각 13까지 준비 큐에서 대기했으므로 대기시간은 (3-2)+(13-6)=8이다.
프로세스 C는 시각 4에 도착하여 시각 10에 종료했으므로 반환시간은 6이다.
또한 시각 9에 디스패치되었으므로 대기시간은 5이다.
프로세스 D는 시각 5에 도착하여 시각 13에 종료했으므로 반환시간은 8이다.
또한 시각 10에 디스패치되었으므로 대기시간은 5이다.
| 프로세스 | A | B | C | D |
|---|---|---|---|---|
| 대기시간 | 3 | 8 | 5 | 5 |
| 반환시간 | 9 | 12 | 6 | 8 |
평균대기시간: 5.25
평균반환시간: 8.75
📄HRN 스케줄링
HRN 또는 HRRN(High Response Ratio Next) 스케줄링은 준비 큐에서 기다리는 프로세스 중 응답비율이 가장 큰 것을 먼저 디스패치하여 실행하는 비선점 방식읜 스케줄링 알고리즘이다.
\[응답비율 = {대기시간 + 예상실행시간 \over 예상실행시간} = {대기시간 \over 예상실행시간} + 1\]응답비율은 예상실행시간이 짧을수록, 대기시간이 길수록 커진다. 따라서 모든 프로세스가 동시에 준비 큐에 들어오면 그 중 예상실행시간이 가장 짧은 프로세스가 선택된다. 그리고 예상실행시간이 모두 동일한 프로세스들이 준비 큐에 들어온 시각이 모두 다르다면 대기시간이 가장 긴 프로세스가 선택된다. HRN 스케줄링도 CPU 사이클이 미리 주어져야만 적용 가능하다.
위에서 예로든 프로세스 도착시간과 CPU사이클에 의한 HRN 스케줄링 알고리즘의 결과는 아래와 같다.
0 6 7 11 14
| A | C | B | D |
| 시각 | 0 | 6 | 7 | 11 | 14 | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 응답비율 | ||||||||||||||||
| A | 1 | |||||||||||||||
| B | 2 | 2.25 | ||||||||||||||
| C | 3 | |||||||||||||||
| D | 1.33 | 1.66 | 6 |
프로세스 A는 시각 0에 도착하여 시각 6에 종료했으므로 반환시간은 6이다.
또한 준비 큐에 도착하고 바로 디스패치되었으므로 대기시간은 0이다.
프로세스 B는 시각 2에 도착하여 시각 11에 종료했으므로 반환시간은 9이다.
또한 시각 7에 디스패치되었으므로 대기시간은 5이다.
프로세스 C는 시각 4에 도착하여 시각 7에 종료했으므로 반환시간은 3이다.
또한 시각 6에 디스패치되었으므로 대기시간은 2이다.
프로세스 D는 시각 5에 도착하여 시각 14에 종료했으므로 반환시간은 9이다.
또한 시각 11에 디스패치되었으므로 대기시간은 6이다.
| 프로세스 | A | B | C | D |
|---|---|---|---|---|
| 대기시간 | 0 | 5 | 2 | 6 |
| 반환시간 | 6 | 9 | 3 | 9 |
평균대기시간: 3.25
평균반환시간: 6.75
📄다단계 큐 스케줄링
다단계 큐(MultiLevel Queue) 스케줄링은 우선순위에 따라 준비 큐를 여러 개 사용하는 스케줄링 알고리즘이다. 프로세스는 우선순위에 따라 해당 우선순위의 큐에 삽입된다. 각각의 큐는 라운드 로빈 방식으로 운영되고 우선순위에 따라 다단계로 나뉘어 있기 때문에 프로세스가 큐에 삽입되는 것만으로 우선순위가 결정된다.
다단계 큐 스케줄링은 우선순위에 맞게 다양한 스케줄링이 가능한 선점형 방식의 알고리즘이다. 우선순위에 따라 프로세스 작동 순서를 바꿀 수 있고 시간할당량을 조절하여 작업 효율을 높일 수 있다. 예를 들어, 전면 프로세스는 반응 속도를 높이기 위해 타임 슬라이스를 작게 하고, 후면 프로세스는 사용자와 상호작용이 없으면 FCFS 방식으로 처리 할 수 있다.
다단계 큐 스케줄링은 우선순위가 높은 상위 큐 프로세스의 작업이 끝나기 전까지 하위 큐 프로세스의 작업을 할 수 없다. 쉽게 말해, 우선순위 1번인 큐에 프로세스가 대기하고 있다면 우선순위 2번인 큐의 프로세스는 1번 큐의 프로세스가 작업을 마칠 때까지 기다려야 한다.
📄다단계 피드백 큐 스케줄링
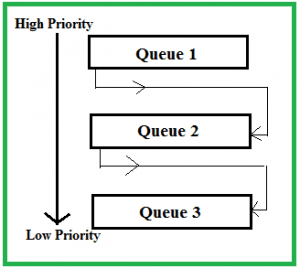
다단계 피드백 큐(MultiLevel Feedback Queue) 스케줄링은 입출력 중심인 프로세스와 연산 중심인 프로세스의 특성에 따라 서로 다른 시간 할당량을 부여하는 선점 방식의 스케줄링 알고리즘이다. 또한 우선순위가 낮은 프로세스에 불리한 다단계 큐 스케줄링의 단점을 보완한 방식이다.
다단계 큐 스케줄링은 각 단계의 큐에 라운드 로빈 방식을 사용하고 우선순위에 변화가 없는데, 다단계 피드백 큐 스케줄링은 CPU를 사용하고 난 프로세스의 우선순위가 낮아진다. 시간 할당량 안에 작업을 끝마치지 못한 프로세스는 원래 큐로 돌아가지 않고 우선순위가 하나 낮은 큐의 끝으로 들어간다.
프로세스가 CPU를 할당받아 실행될 때마다 프로세스의 우선순위를 낮춤으로써 우선순위가 낮은 프로세스의 실행이 연기되는 문제를 완화했다. 그리고 다단계 피드백 큐 스케줄링에서 우선순위에 따라 시간 할당량의 크기가 다르다는 특징이 있다. 프로세스의 우선순위가 낮아질수록 해당 큐의 시간 할당량은 커진다. 우선순위가 낮은 프로세스가 우선순위가 높은 프로세스보다 CPU를 얻을 확률이 더 낮기 때문에 CPU를 할당받으면 작업을 더 오래할 수 있도록 우선순위가 낮은 큐의 시간 할당량을 크게 설정한 것이다.
다단계 피드백 큐 스케줄링의 마지막 큐에 있는 프로세스는 무한대의 시간 할당량을 얻는다. 따라서 마지막 큐의 프로세스가 실행상태에 들어가면 CPU를 뺏기지 않고 끝까지 작업을 마칠 수 있다. 들어온 순서대로 작업을 마치기 때문에 마지막 큐는 FCFS 스케줄링 방식으로 동작한다.
출처
https://www.geeksforgeeks.org/multilevel-feedback-queue-scheduling-mlfq-cpu-scheduling/
Leave a comment